TUGAS KULIAH BAB V
MOMEN KEMIRINGAN DAN KURTOSIS
- Momen
Misal diketahui variabel X dengan harga X1, X2, X3 . . . . Xn. Jika A sebuah bilangan tetap dan r = 0, 1, 2, 3, maka momen di sekitar A disingkat m’rdidefinisikan oleh
Dengan
n = , Xi = tanda kelas interval dan fi = frekuensi yang sesuai dengan Xi.
Dengan menggunakan cara coding, rumusnya:
m’r = , P = Panjang kelas, C = Variabel koding.
Dari m’r harga-harga mr dapat ditentukan berdasarkan hubungan:
m2 = m2’ – (m1’)2
m3 = m3’ – 3m1’ + m2 + 2(m1’)3
m4 = m4’ – 4m1’ + 6 (m1’) m2 – 3 (m1’)
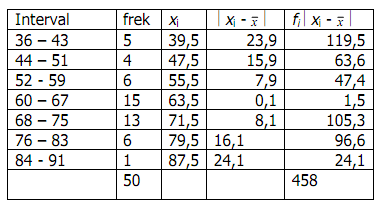
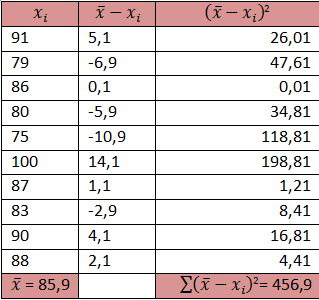
Untuk menghitung momen disekitar rata-rata, untuk data dalam daftar distribusi frekuensi, kita lakukan sebagai berikut:
TABLE 5.1: Table pembantu untuk mencari m
Data
|
f1
|
Ci
|
f1Ci
|
f1C12
|
f1C13
|
f1C14
|
60 – 63
64 – 67
68 – 71
72 – 75
76 – 70
|
5
18
42
27
8
|
-2
-1
0
1
2
|
-10
-18
0
27
16
|
20
18
0
37
42
|
-40
-18
0
27
64
|
80
18
0
27
128
|
Jumlah
|
100
|
15
|
97
|
35
|
253
|
Dapat dihitung:
Sehingga dengan menggunakan hubungan di atas:
m2 = m2’ – (m1’)2 = 15,52 – 0,36 = 15,16
m3 = m3’ – 3m1’ m2’ + 2(m1’)3 = 5,28 – 3x0,6x15,52 +2x (0,6) = 21,456
m4 = m4’ – 4m1’ m3’ + 6 (m1’)2 (m2’)...........
= 40,48 – 4x0,6 x 5,28 + 6 x 0,6 2x15,52 – 3x0,42
= 60,9424
Jadi Varian S2 = m2 = 15,16
B.KEMIRINGAN
Kurva distribusi normal, yang tidak terlalu rucing atau tidak terlalu datar. Dinamakanmesokurtik,
kurva yang runcing dinamakan leptokurtik sedangkan yang datar disebut platikurtik.
Salah satu ukuran kurtosis ialah koefisien kurtosis, diberi simbol a4, ditentukan denganrumus a4 = (m4/m)
Kriteria yang didapat dari rumus ini ialah:
a) a4 = 3 à Distribusi normal
b) a4 > 3 à Distribusi yagn leptokurtik
c) a4 < 3 à Distribusi yang platikurtik
Untuk mengetahui apakah distribusi normal atau tidak sering pula dipakai koefisien kurtosis persentil, diberi simbul:
κ =
SK = rentang semi antar kuartil
K3 = kuartik ketiga
K1 = kuartil kedua
P10 = persentil kesepuluh
P90 = persentil ke 90
Untuk distribusi normal, harga κ = 0,263
Untuk contoh di atas telah di dapat m4 = 60,9424, sedangkan m = 15,17 sehingga besarnya koefisien kurtosis a4 = (m4/m) = 60,9424/229,8256 = 0,265, ini kurang dari 3, jadi kurvanya cenderung aman platikurtik.
Contoh: data nilai ujian Fisika dasar dari 80 mahasiswa, akan kita cari koefisien kurtosis persentil besarnya:
Dimana K1 dan K3 telah kita hitung; K1 = 81,676 dan K3 = 61,75, adapun datanya telah disusun dalam daftar sebagai berikut:
No
|
Nilai Ujian
|
Fi
|
1
2
3
4
5
6
7
|
31 – 40
41 – 50
51 – 60
61 – 70
71 – 80
81 – 90
91 – 100
|
3
5
10
16
24
17
5
|
Jumlah
|
80
|
Dengan menggunakan rumus Pi = b + P dimana P = panjang kelas dapat dihitung P10 dan P90.
P10 akan terletak pada data ke , yaitu pada kelas interval ke 2 sehingga b = 40,5, P = 10; F = 3 f = 5
P10 = 40,5 + 10 = 50,5
P90 akan terletak pada data ke , yaitu pada kelas interval keenam, sehingga b = 80,5, P = 10, F = 8, f = 17
P90 = 80,5 + 10 = 81,32
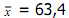
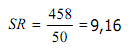
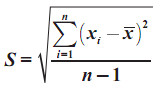

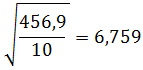
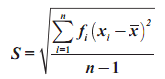



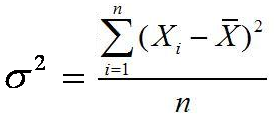
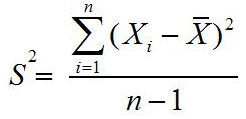
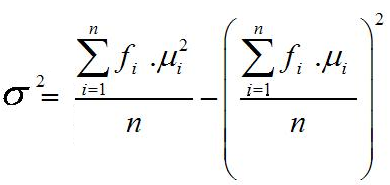
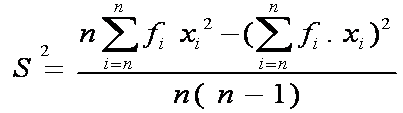

{kind=link}